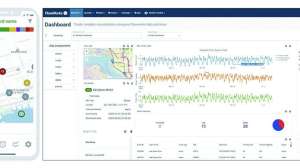
Small, rural drinking water treatment plants often use chlorine to implement the disinfection process. A key performance measure for disinfection is free chlorine residual, the concentration of free chlorine remaining in the water after the chlorine has oxidized the target contaminants. Plant operators choose a dose of chlorine to achieve a satisfactory concentration, but must often estimate chlorine requirements.
The challenge of determining an accurate concentration of chlorine has led to the use of advanced prediction techniques, including machine learning. By identifying correlations among numerous variables in complex systems, machine learning could be used to accurately predict free chlorine residual, even